Abstract
Dump pocket blockages at primary crushers cause production downtime and require manual clearing in hazardous restricted areas, with documented engulfment fatalities in hoppers and crusher zones. Autonomous approaches for dump pocket cleaning and blocked-crusher clearing remain limited, and the feasibility of state-of-the-art imitation learning (IL) for this excavation task remains largely unexplored. This paper introduces an experimental testbed and benchmark for evaluating IL architectures on autonomous dump pocket cleaning under controlled laboratory conditions. We benchmark four IL architectures: Action Chunking with Transformers (ACT), Diffusion Policy, and Vision-Language-Action models (π₀.₅ and SmolVLA), using a low-cost SO-ARM100 platform ($250) with granular bentonite material. In a preliminary single-session evaluation (10 minutes per model), π₀.₅ achieves the highest removal rate at 404 g, reaching 65% of the expert teleoperation estimate, followed by ACT (169 g), SmolVLA (113 g), and Diffusion Policy (57 g). π₀.₅'s lead is consistent with potential advantages from larger model capacity (3.7B vs. 450M parameters) and broader pretraining across diverse robot embodiments and tasks. ACT, trained from scratch on the same dataset, outperforms SmolVLA in this single-session benchmark, raising the hypothesis that for narrow single-task settings where the target domain differs from pretraining data, learning from scratch may remain competitive with fine-tuning a pretrained model. Diffusion Policy removes the least material, consistent with its visibly slower reactive behavior during rollout. This work establishes an open dataset (162 demonstrations) and a reproducible testbed to support future research on autonomous tasks for the mining industry.
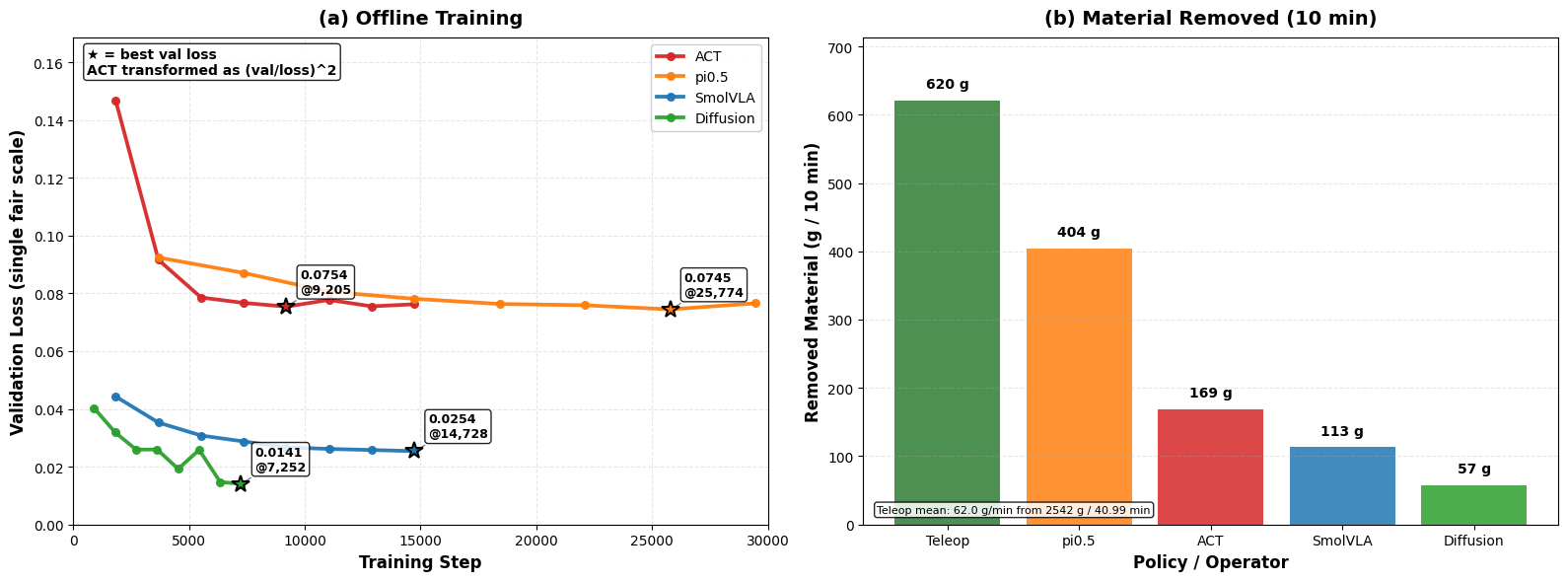
Key Results
Single 10-minute autonomous session per model. Expert baseline estimated from demonstration data (62.04 g/min × 10 min). N=1 session per model — values represent single observed measurements.
| Model | Removed (g / 10 min) | Rate (g/min) | % of Expert (est.) |
|---|---|---|---|
| Expert Teleoperation (est.) | ≈ 620 | 62.0 | 100% |
| π₀.₅ (VLA) | 404 | 40.4 | 65% |
| ACT | 169 | 16.9 | 27% |
| SmolVLA | 113 | 11.3 | 18% |
| Diffusion Policy | 57 | 5.7 | 9% |
These are exploratory observations pending systematic replication. Cross-architecture comparison is based on real-robot removed mass, not validation loss, because the models optimize different training objectives.
Scope, Limitations, and Transfer
The benchmark demonstrates laboratory feasibility in a simplified dump-pocket analogue, not mine-ready deployment. The testbed uses bentonite rather than heterogeneous ore, operates at roughly 1000× smaller scale than industrial hoppers (0.016 vs. 10–50 m³), and does not include dust, poor lighting, vibration, or mine-scale sensing constraints.
Scaling to industrial embodiments also requires new demonstrations on the target hardware. The algorithmic workflow may transfer, and the current dataset may support benchmarking or pretraining, but final deployment data must be collected at the relevant scale and hardware. This lab-to-mine data and embodiment gap is the primary limitation.
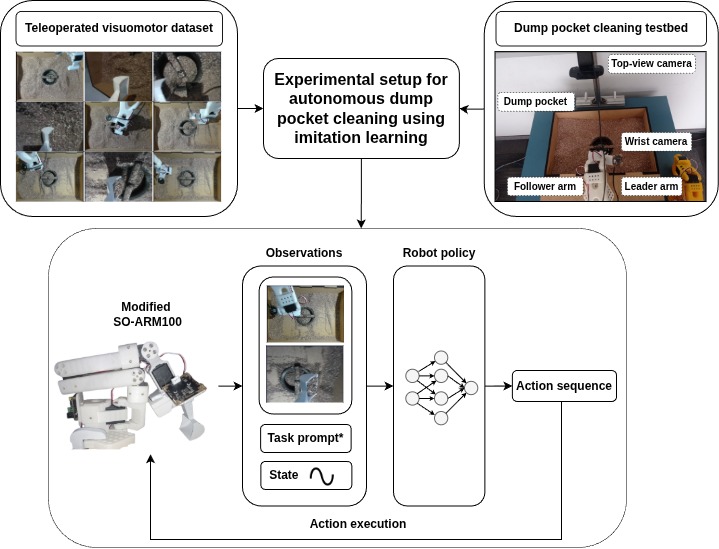
Testbed Contribution
The project provides a lab-scale dump-pocket testbed built on the open-source SO-ARM100 low-cost robot platform, rather than a proprietary arm design. The contribution is the mining task formulation, dataset, benchmark protocol, custom bucket setup, and reproducible evaluation pipeline for comparing imitation learning methods in a dump-pocket cleaning analogue.
Success Rollouts
One representative autonomous run per model (10-minute session, muted). Filmed with the overhead and wrist cameras used during evaluation.
Figures
Resources
Dataset
Citation
@inproceedings{meza2026autonomous,
title={A Robotic Testbed for Autonomous Dump Pocket Cleaning Using Imitation Learning},
author={Meza Pinedo, Brik Henrry and Pajares Correa, Brian},
booktitle={World Mining Congress 2026},
year={2026}
}Acknowledgments
We thank NONHUMAN for providing laboratory facilities and infrastructure support that enabled this research. We are grateful to the open-source robotics community, particularly the developers of the SO-ARM100 platform and the open-source robot learning library, whose accessible tools and collaborative spirit made these experiments possible. We also acknowledge PUCP for institutional support.